Cloud Resume Challenge
A cloud resume implementation on GCP and Cloudflare, automated with Terraform and Ansible, and operated with full Datadog observability.
"Designed, built, automated, operated, and debugged end-to-end with practical tradeoffs in reliability, security, cost, and maintainability."
Quick Facts
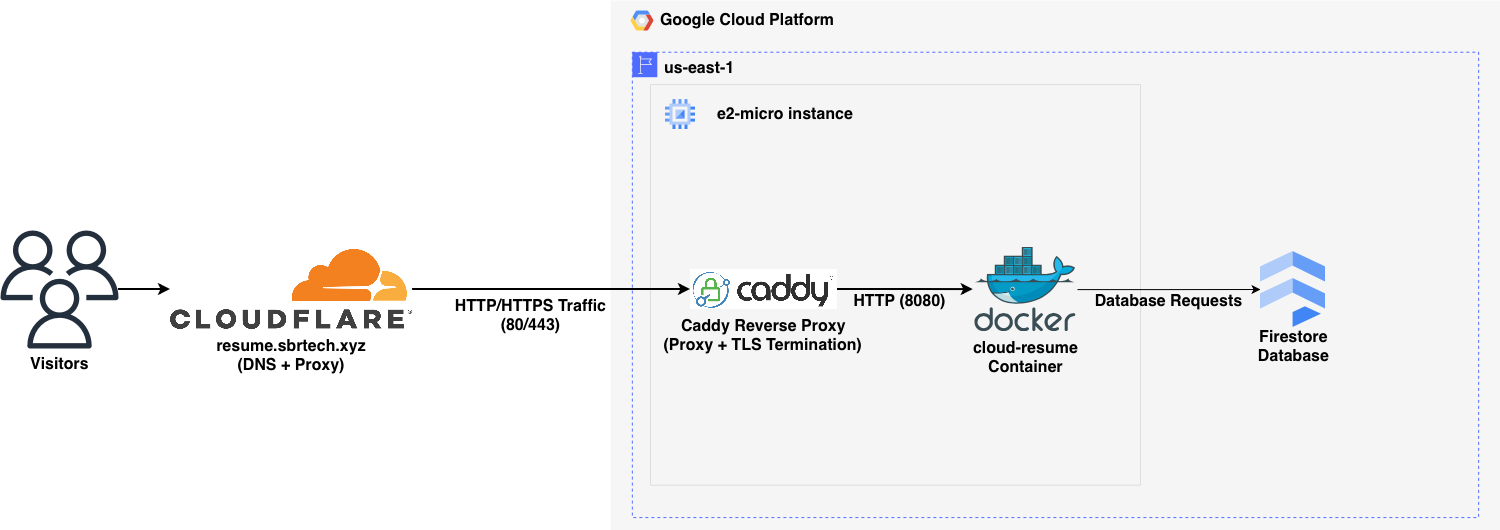
Production Architecture at a Glance
Complete Ownership
Provisioned GCP and Cloudflare with Terraform, configured the host with Ansible, and deployed a containerized Flask/Gunicorn app.
Secure System Flow
Cloudflare proxy and WAF in front of Caddy TLS, Cloudflare-only origin firewall rules, and IAM-based Firestore access.
Edge-First Strategy
Traffic enters through Cloudflare for DDoS mitigation and caching, then routes through Caddy to the app while preserving real client IPs.
Operational Maturity & Observability
Monitoring is focused on useful signals: synthetic /healthz checks, APM traces, structured JSON logs, dashboards, monitors, and SLO tracking in Datadog.
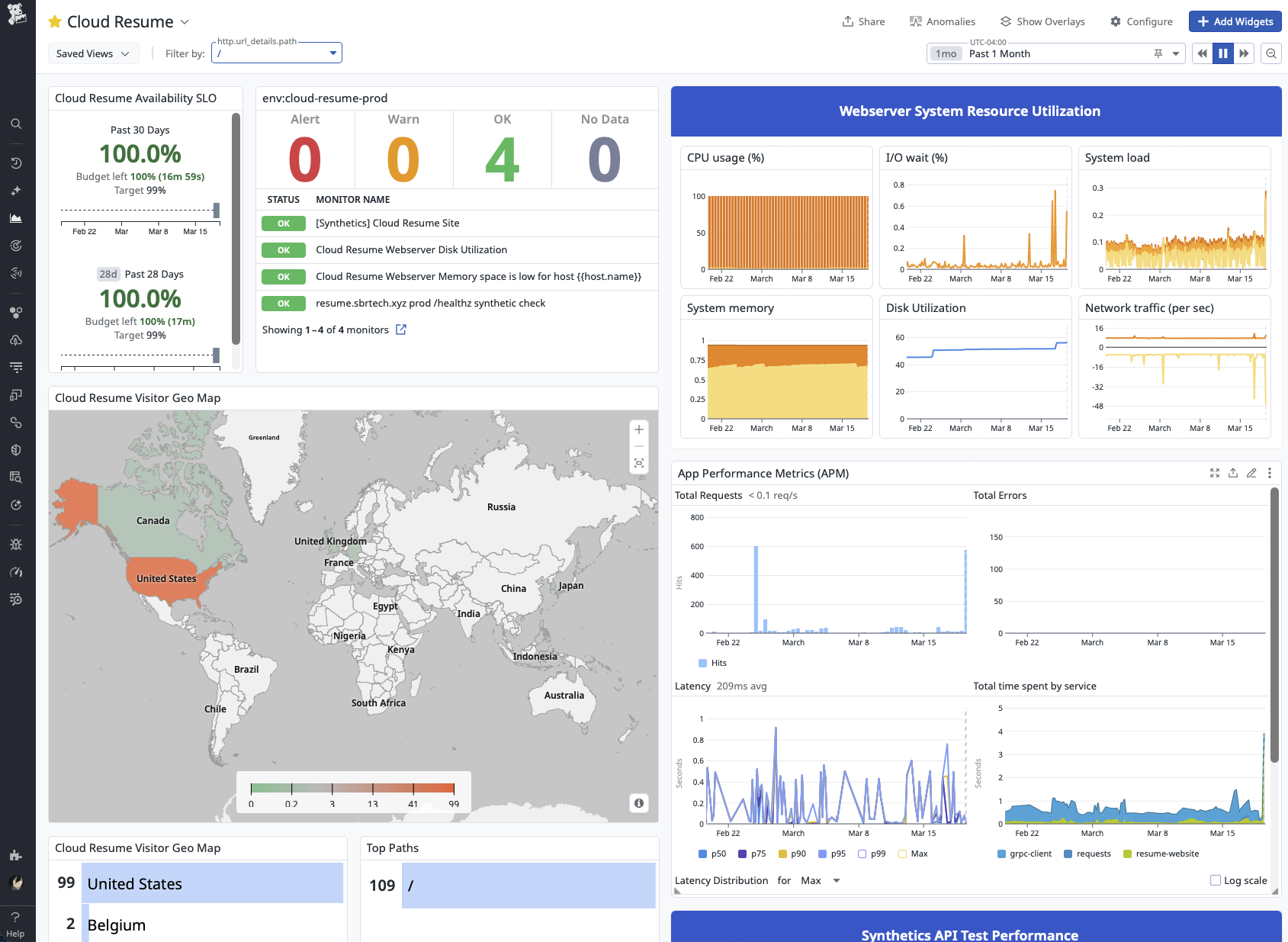
Datadog Dashboard, APM & Logs
Synthetic Monitoring
A Datadog Synthetic API test checks /healthz so uptime monitoring never increments the visitor counter.
Dashboard & SLO Tracking
Monitors, service health, host metrics, traffic, logs, and synthetic performance are consolidated into one daily-use operations view.
Log Aggregation
Structured JSON logs and trace correlation make it fast to move from a symptom to the exact request that caused it.
Engineering Highlights
Automation
Terraform provisions infrastructure, Ansible configures the host and deploys the container, and GitHub Actions drives the release workflow.
Security & Edge
Cloudflare adds DDoS protection, WAF filtering, and edge caching while Caddy automates TLS and forwards trusted client IPs to the app. Fail2ban protects SSH against brute-force attacks.
Cost-Aware
24-hour in-memory dedup cache cuts Firestore operations to preserve free-tier limits and reduce database cost.
Troubleshooting
Diagnosed and resolved severe production iowait that was stalling deploys and degrading availability on a resource constrained host.
The Production Incident: Diagnosing Severe iowait
Once the stack went live on an e2-micro host, severe iowait started stalling deploys and threatening availability. The eventual root cause wasn’t where I expected, and it changed how I think about constraints and diagnostics.
Read the Lessons Learned launch
[WARN] Deploy latency
spiking; host responsiveness degraded.
[WARN] Page timeouts
increasing!
[ERROR] Host SSH connection
has been lost.......reconnection attempt [15/30]